
Mingqian Feng
Ph.D. Candidate, University of Rochester CS
mingqian.feng@rochester.edu
Bio
I am a third-year Ph.D. candidate in the Department of Computer Science at University of Rochester (UR), where I am fortunate to be advised by Prof. Chenliang Xu. Prior to that, I received my M.S.E degree in Financial Mathematics at Johns Hopkins University (JHU). and my B.Sc. degree in physics at University of Science and Technology of China (USTC).
I am broadly interested in: - Trustworthy AI: hallucination, bias, privacy, and explainability; - Forward Learning: likelihood ratio method, zeroth-order optimization; - MLLM: Audio-visual LLM, Video LLM;
I am actively looking for collaboration on research. If you share similar interests, please feel free to contact me!
News
Publications
Google Scholar.
* indicates equal contribution.

Do More Details Always Introduce More Hallucinations in LVLM-based Image Captioning?
Mingqian Feng, Yunlong Tang, Zeliang Zhang, Chenliang Xu
Preprint arXiv 2024.
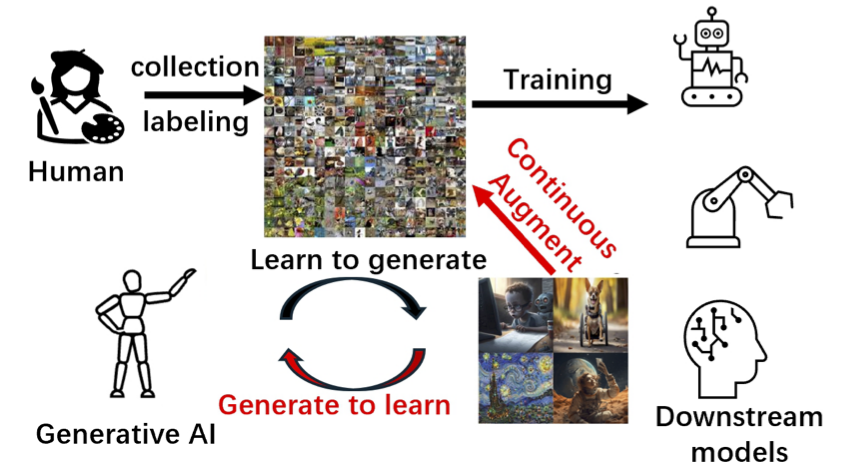
Will the Inclusion of Generated Data Amplify Bias Across Generations in Future Image Classification Models?
Zeliang Zhang, Xin Liang, Mingqian Feng, Susan Liang, Chenliang Xu
Preprint arXiv 2024.

Can CLIP Count Stars? An Empirical Study on Quantity Bias in CLIP
Zeliang Zhang, Zhuo Liu, Mingqian Feng, Chenliang Xu
Preprint arXiv 2024.
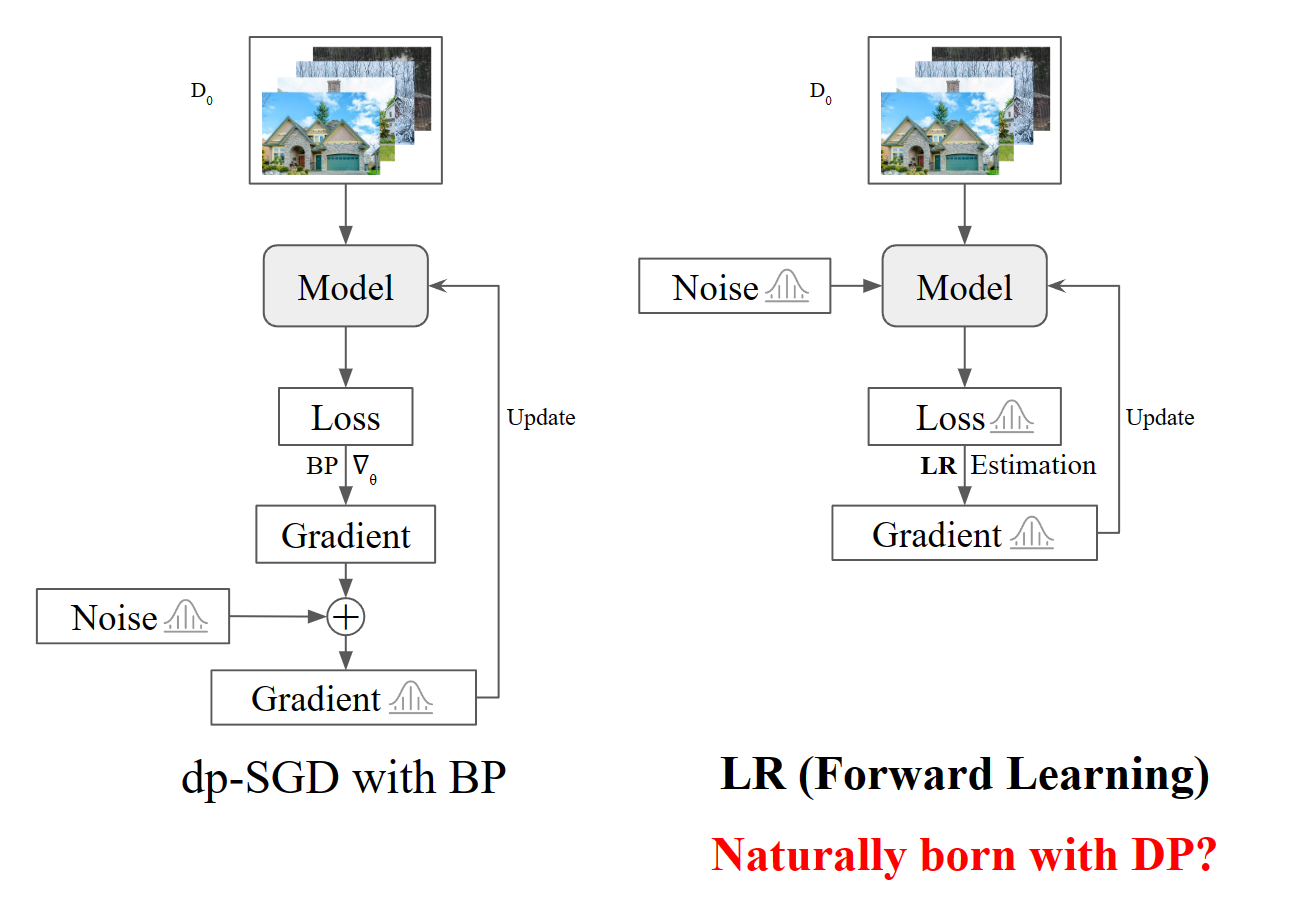
Forward Learning with Differential Privacy
Mingqian Feng, Jinyang Jiang, Zeliang Zhang, Chenliang Xu
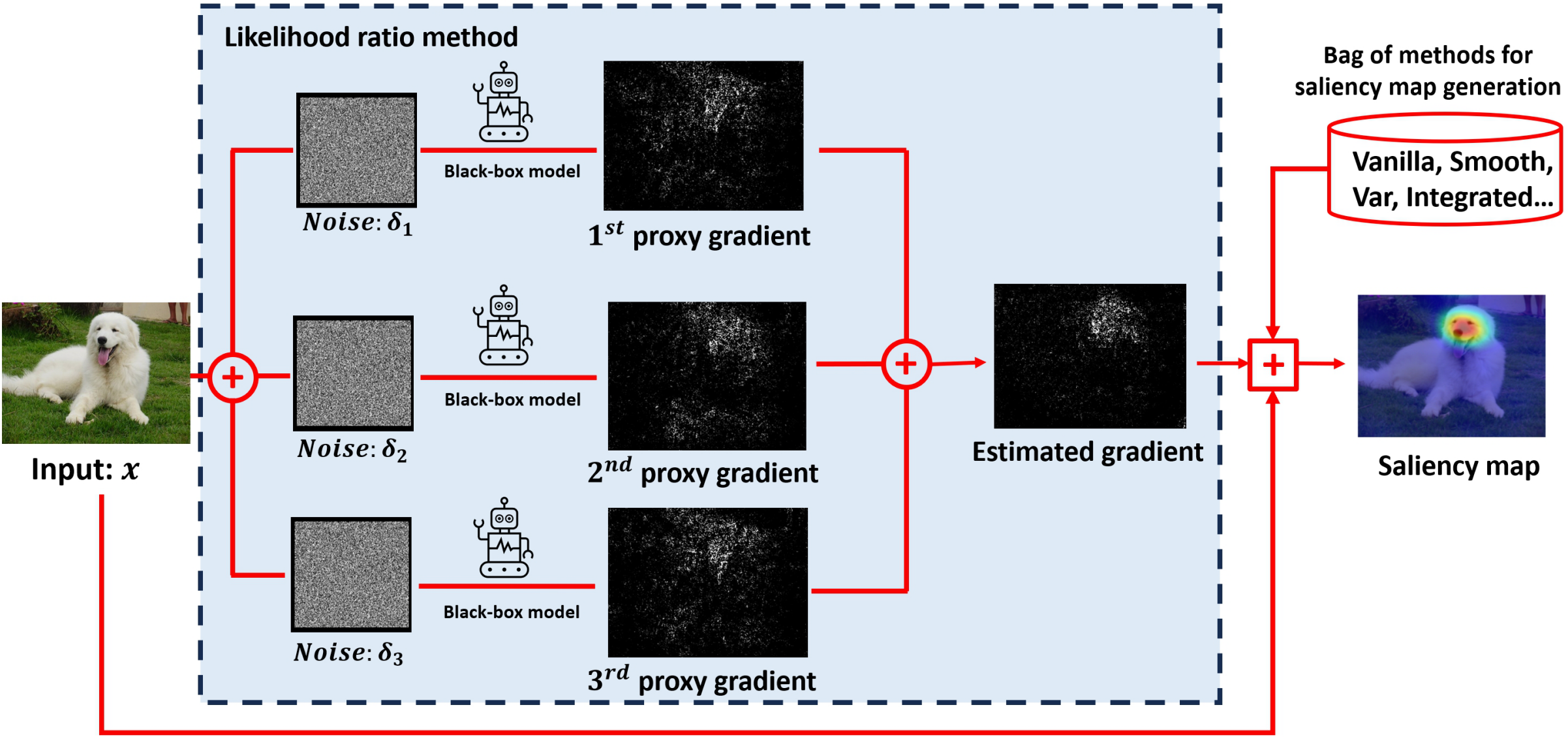
Forward Learning for Gradient-based Black-box Saliency Map Generation
Mingqian Feng*, Zeliang Zhang*, Jinyang Jiang, Rongyi Zhu, Yijie Peng, Chenliang Xu
Preprint arXiv 2024.
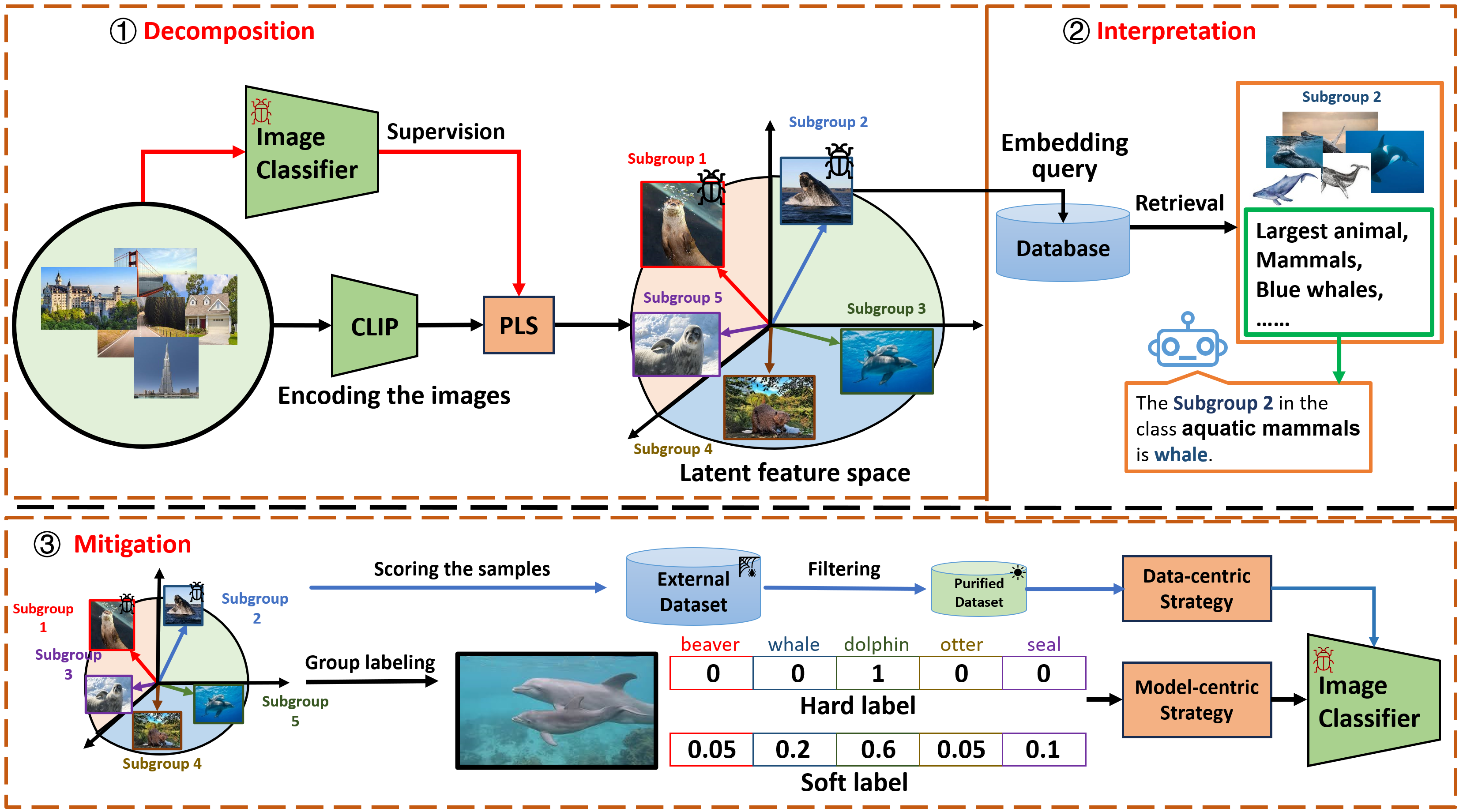
Discover and Mitigate Multiple Biased Subgroups in Image Classifiers
Mingqian Feng*, Zeliang Zhang*, Jinyang Jiang, Rongyi Zhu, Yijie Peng, Chenliang Xu
CVPR 2024.
Do More Details Always Introduce More Hallucinations in LVLM-based Image Captioning?
Mingqian Feng, Yunlong Tang, Zeliang Zhang, Chenliang Xu
Preprint arXiv 2024.
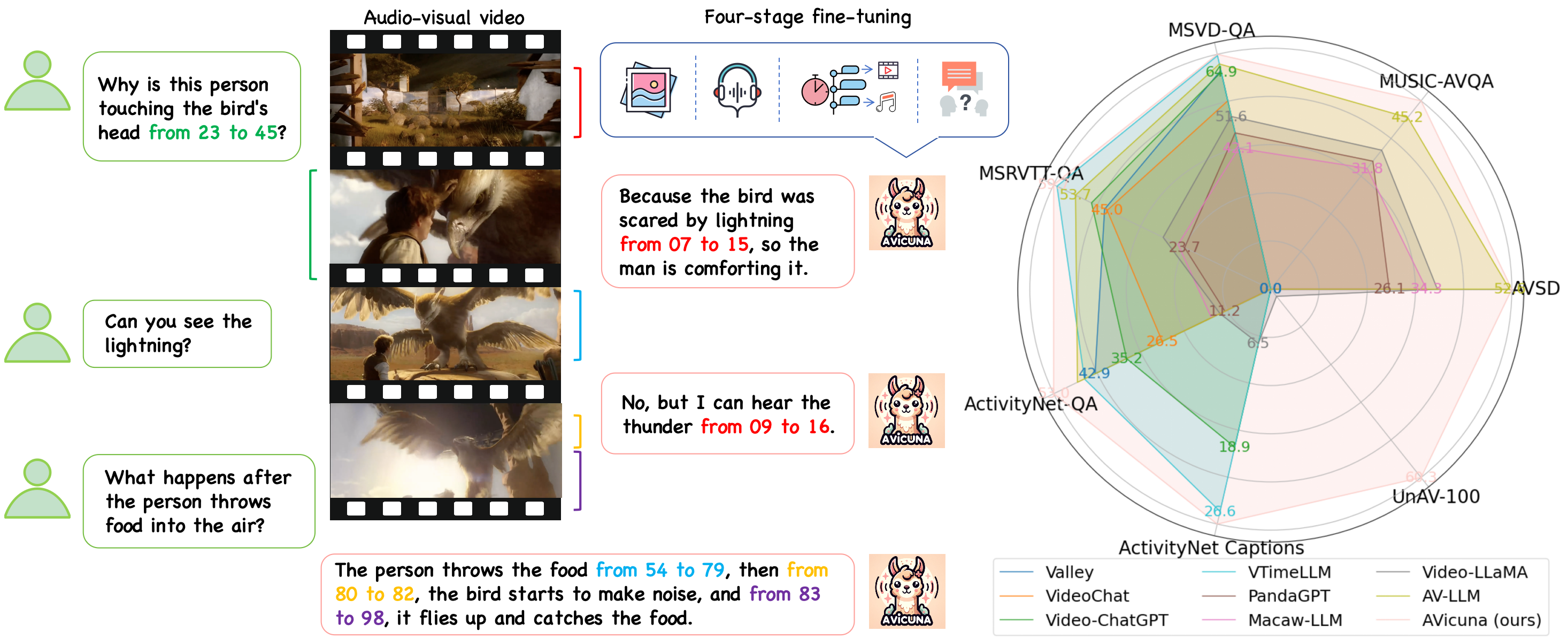
Empowering LLMs with Pseudo-Untrimmed Videos for Audio-Visual Temporal Understanding
Yunlong Tang, Daiki Shimada, Jing Bi, Mingqian Feng, Hang Hua, Chenliang Xu
Preprint arXiv 2024.
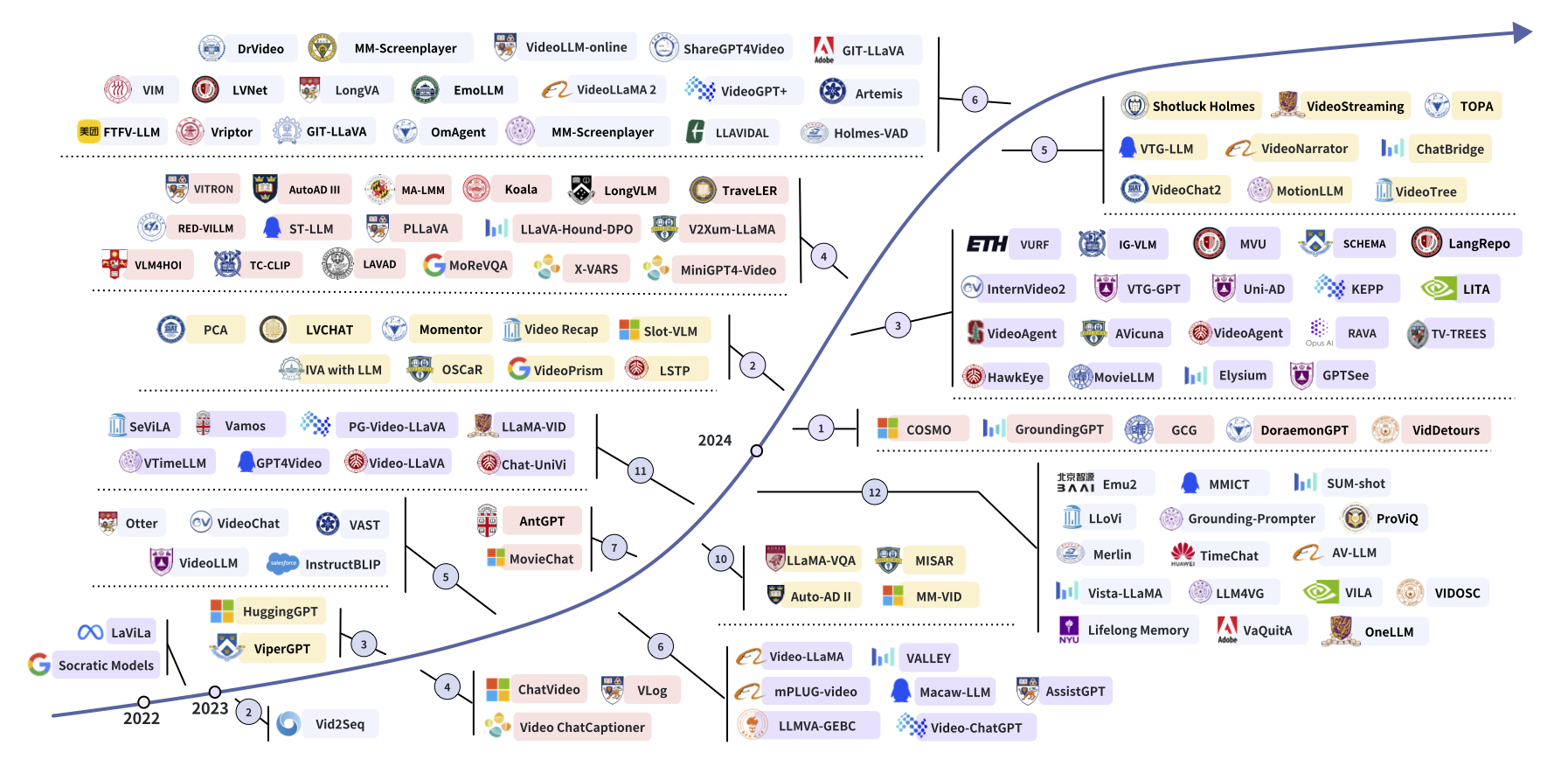
Video Understanding with Large Language Models: A Survey
Yunlong Tang, Jing Bi, Siting Xu, …, Mingqian Feng, …, Jiebo Luo, Chenliang Xu
Preprint arXiv 2024.
Forward Learning with Differential Privacy
Mingqian Feng, Jinyang Jiang, Zeliang Zhang, Chenliang Xu
Forward Learning for Gradient-based Black-box Saliency Map Generation
Mingqian Feng*, Zeliang Zhang*, Jinyang Jiang, Rongyi Zhu, Yijie Peng, Chenliang Xu
Preprint arXiv 2024.
Do More Details Always Introduce More Hallucinations in LVLM-based Image Captioning?
Mingqian Feng, Yunlong Tang, Zeliang Zhang, Chenliang Xu
Preprint arXiv 2024.
Will the Inclusion of Generated Data Amplify Bias Across Generations in Future Image Classification Models?
Zeliang Zhang, Xin Liang, Mingqian Feng, Susan Liang, Chenliang Xu
Preprint arXiv 2024.
Empowering LLMs with Pseudo-Untrimmed Videos for Audio-Visual Temporal Understanding
Yunlong Tang, Daiki Shimada, Jing Bi, Mingqian Feng, Hang Hua, Chenliang Xu
Preprint arXiv 2024.
Video Understanding with Large Language Models: A Survey
Yunlong Tang, Jing Bi, Siting Xu, …, Mingqian Feng, …, Jiebo Luo, Chenliang Xu
Preprint arXiv 2024.
Can CLIP Count Stars? An Empirical Study on Quantity Bias in CLIP
Zeliang Zhang, Zhuo Liu, Mingqian Feng, Chenliang Xu
Preprint arXiv 2024.
Forward Learning with Differential Privacy
Mingqian Feng, Jinyang Jiang, Zeliang Zhang, Chenliang Xu
Forward Learning for Gradient-based Black-box Saliency Map Generation
Mingqian Feng*, Zeliang Zhang*, Jinyang Jiang, Rongyi Zhu, Yijie Peng, Chenliang Xu
Preprint arXiv 2024.
Discover and Mitigate Multiple Biased Subgroups in Image Classifiers
Mingqian Feng*, Zeliang Zhang*, Jinyang Jiang, Rongyi Zhu, Yijie Peng, Chenliang Xu
CVPR 2024.
Education
Experiences
Misc.
Fun facts:
- I ventured through three distinct majors during my undergrad, master's, and doctoral journeys, which makes me deeply thankful for finally finding my true passion before bidding farewell to campus life.
- I love to design and host activities for friends to get together. See invitation examples [1][2] [3].
- I am blessed with friends and family who offer me their unwavering support. Love you guys.
![[1]](./assets/misc/just_wanna_invitation.jpg){kind=link}
![[2]](./assets/misc/jhu_graduation_invitation.jpg){kind=link}
![[3]](./assets/misc/bananana_invitation.PNG){kind=link}
Pipe dreams:
- May all in this world be free from illness' blight, without lamenting the dusty shelves where medicines recline.
- To live in latant space of foundation models and feel the "physical" properties there.
- "Because it's there." ——George Mallory